Presentation Files - Our application got popular and now it breaks!
 Posted By : Dan Wilson
Posted By : Dan Wilson
 May 14, 2015 12:38 PM
May 14, 2015 12:38 PM
I've just posted the presentation "Our application got popular and now it breaks!" that was delivered at Dev.Objective() 15. If you were at the conference and would like the presentation files, you can find a PDF version here. You can also view this presentation on Slideshare
So you helped build a cool application and the public is flooding your site with traffic. What's that smell? Is a server on fire? Oh No! If only you'd thought more about the performance implications of some of your decisions, things would be better. Now, the phones ring at 4AM with angry customers, rousing you out of bed. There isn't enough coffee in the world to get you through these disastrous weeks ahead. You could have avoided all of this by coming to this session.
Bullet Points:
- Simple design decisions that come back to bite you
- How to use infrastructure for fun and profit
- Making the data tier work for you
- Performance traps and how to get out of them
- How to be sure your application can handle popularity
- The audience should have a working knowledge of server programming


The Top 5 Things You are Doing Today to Hinder Scalability
Posted By : Dan Wilson
October 22, 2014 11:07 AM
At the CFSummit 2014, I presented on The Top 5 Things You are Doing Today to Hinder Scalability.
I collected my material through helping clients to scale their applications over a number of years. The important things in this presentation are listed in order. Decisions you make in your applications today, affect what options you have when you need to scale your application.
Certainly it is a very good thing to have an application you built grow to the point you need to consider scalability. Popularity is good, right?
However, there are decisions you can make in your code, code architecture and infrastructure architecture that will add or remove scalability options.
The presentation was well received by the audience and I thank each and every one of them for choosing to spend their time with me during this time slot.
For brevity, I included a number of details in an appendix to the presentation. Review this if you want to know particulars about a specific topic.
You can review the slide deck here: http://www.slideshare.net/ColdFusionConference/top5-scalabilityissues.
I'm always available for questions or consulting, should you need extra help.
I hope you enjoyed the CFSummit 2014. See you next year!
Using MongoDB Aggregation Framework to Filter Trello Cards
Posted By : Dan Wilson
July 23, 2013 9:14 AM
I'm helping prepare the CFSummit conference. We've organized the sessions on Trello and had a public voting session. It's time to start organizing the topics into a schedule.
In a conference schedule, it's important to know which sessions will be popular. It's desirable to ensure the most desirable sessions do not compete with each other. Thus, I wanted to pull out the sessions and organize the sessions by popularity.
The MongoDB Aggregation Framework
The MongoDB aggregation framework is a relatively new addition to the platform. Using this framework, you can group, sort, calculate and handle information gathering in the aggregate sense. Here's how I did this for the Trello Json data.
The Mongo Query
Exporting out of Trello gives a big JSON document with JSON members for each card. It turns out, in our case, all of the cards we want belong to a specific list. Once we pull the correct cards, we want to sort them by their votes. We'll end up with a sorted array of sessions by popularity. Here is the MongoDB query:
2 {$project: { "cards": "$cards"}},
3 {$unwind: "$cards"},
4 {$match: {"cards.idList": {"$in": ["51c9aa15d0b4871a3e000075"]}}},
5 {$project: {"_id": 1, "name": "$cards.name", "members": "$cards.idMembers", "url": "$cards.url", "votes": "$cards.badges.votes"}},
6 {$sort: {votes:-1}}
7])
Explained Line by Line:
db.cfsummit.aggregate([Notice the argument to the aggregate command is an array? This means you can organize a series of document transformations into steps. Each step will manipulate the document in some fashion. Let's look at our first step in the transformation:
{$project: { "cards": "$cards"}},
The first transformation is a $project command. Project (Pro-JECT), means to project a new way to view the data. In this case, I'm only interested in the cards node. The result of this document is a new document with basically only the cards member. You can write queries without $project, but I always do use it for 2 reasons. Firstly, reducing the size of the working document makes the query more efficient. The resulting projected document is smaller and can more easily be manipulated. The second reasons is I write my queries incrementally, so I only need to see, what I need to see. (Note the cards member is an array, this is important in the next step)
2 {
3 "_id" : ObjectId("51ee98afaa17829291af81e0"),
4 "cards" : [
5 {
6 "id" : "51b0fbec94b2237145005a18",
7 "badges" : {
8 "votes" : 0,
9 "viewingMemberVoted" : false,
10 "subscribed" : false,
11.....
{$unwind: "$cards"},
Now the card nodes is an array. I'm going to want to sort all of the matching cards by the votes parameter. I use an $unwind command to transform the cards array members into their own documents.
2 {
3 "_id" : ObjectId("51ee98afaa17829291af81e0"),
4 "cards" : {
5 "id" : "51b0fbec94b2237145005a18",
6 "badges" : {
7 "votes" : 0,
8 "viewingMemberVoted" : false,
9 "subscribed" : false,
10...
Note, the cards member is no longer an array... this is important for grouping, which we will do later.
{$match: {"cards.idList": {"$in": ["51c9aa15d0b4871a3e000075"]}}}
Each of the cards we want to deal with belongs to listId: 51c9aa15d0b4871a3e000075. So we use the $match command to match the cards with the listId we are looking for. (Think of this like a where clause in SQL, if that is your background.
2 {
3 "_id" : ObjectId("51ee98afaa17829291af81e0"),
4 "cards" : {
5 "id" : "51b0fbec94b2237145005a18",
6 "badges" : {
7 "votes" : 0,
8 "viewingMemberVoted" : false,
9 "subscribed" : false,
10...
{$project: {"_id": 1, "name": "$cards.name", "members": "$cards.idMembers", "url": "$cards.url", "votes": "$cards.badges.votes"}},
Now I have my sorted cards belonging to the correct list. I now want to set up the return data structure in a way that is most useful to me. In my case, I want the ID, Name of the Session, The Presenters, The Trello URL for the card and the Votes Received. We once again use a $project command to organize the data in the format we want. Note, I've used a dot delimited path to walk the JSON tree to the data member I want. Hence, the votes were in the Votes Node which is inside the Badges Node which is inside the Cards node.
{$sort: {votes:-1}}
Lastly, we need to sort the cards by their popularity. The $sort command takes a JSON object containing the nodes you want to sort by. We want most votes to appear first, so we assign a -1 to the votes column for descending sort. Changing this to 1, would sort the data in an ascending manner.
Final Data Result
2 "result" : [
3 {
4 "_id" : "51ee98afaa17829291af81e0",
5 "name" : "Security Best Practices",
6 "members" : [
7 "51b0ff9bf9d2b2b94c0027bd"
8 ],
9 "url" : "https://trello.com/c/ITpzm0xS/15-security-best-practices",
10 "votes" : 45
11 },
12 {
13 "_id" : "51ee98afaa17829291af81e0",
14 "name" : "ColdFusion Object Oriented Advanced",
15 "members" : [
16 "519a266b522736c97000a224"
17 ],
18 "url" : "https://trello.com/c/1DV4Ud2Z/41-coldfusion-object-oriented-advanced",
19 "votes" : 43
20 },
21 {
22 "_id" : "51ee98afaa17829291af81e0",
23 "name" : "REST 101",
24 "members" : [
25 "50997edfdcb1ac3f1c00ac66"
26 ],
27 "url" : "https://trello.com/c/1oYg37pV/23-rest-101",
28 "votes" : 34
29 },
30....
Want More Information?
Learn more about the MongoDB Aggregation Framework at their documentation site. You can install MongoDB in very little time and start working with data.
Free Training
If you want a more structured training, 10Gen offers a 7 week online training class on MongoDB for free. The classes are very well done. Consider a class if you are Mongo-Curious.
Caching for Fun and Profit: Or why would you ever cache a page for 5 seconds?
Posted By : Dan Wilson
July 21, 2012 10:12 AM
There are a lot of ways to cache data. You can cache a piece of data, a query, a page fragment, an entire page, or an entire website. You can cache to local memory, local file storage, distributed memory, distributed file storage, a front cache, or a Content Delivery Network (CDN). You can cache for ever, until the process regenerates, 5 years, 5 months, 5 days, 5 hours or 5 minutes. Heck, it might even, depending on the system, make sense to cache something for 5 seconds. Maybe less.
Why would I cache something for 5 seconds?
I know, I know, it seems silly to cache something for 5 seconds. You probably think this is a silly attempt at a ridiculous headline to grab clicks. However, let's explore. To get much benefit from caching, cache the content longer than the service time. The service time is the total amount of time it takes to service the request and return the desired item. As an example, if a piece of content takes 5 seconds to generate, the service time is 5 seconds. To get any real benefit, we should cache the content for longer than 5 seconds.What happens if the service time is longer than the cache time?
If the service time is longer than the cache time, requests for the piece of content will queue. With caching, we want to AVOID queuing, so it's important to know the service time of the call under a variety of circumstances. You mathematical types can read up on Little's law, if you are curious: http://en.wikipedia.org/wiki/Little%27s_lawA practical example
Now, most cachable content has a service time of less than 5 seconds. Let's talk about what would happen in 2 identical systems. To make things simple, we'll pretend the following:- There is only one process
- The service time of the process is 1 second
- The request levels are 1, 5, 15 and 30 requests per second.
- The non-cached system is real time, the cached system is cached for 5 seconds
- 3,600 @ 1 RPS
- 18,000 @ 5 RPS
- 54,000 @ 15 RPS
- 108,000 @ 30 RPS
- 720 @ 1 RPS
- 720 @ 5 RPS
- 720 @ 15 RPS
- 720 @ 30 RPS
Let's look at the amount of requests we save at each of the levels:
- 3,600-720=2,880 @ 1 RPS
- 18,000-720=17,280 @ 5 RPS
- 54,000-720=53,280 @ 15 RPS
- 108,000-720=107,280 @ 30 RPS
Wow! By caching for 5 seconds, we saved between 2,800 = 107,280 requests per hour.
What's more interesting we can see we established a service ceiling for our system. We'll never generate more than 720 requests an hour. No matter how many times the link goes viral on www.FunnyCats.com. As traffic rates increase, the value from a 5 second cache also increases. In a world full of email blasts, viral links, email, IM, social media, we see more and more bursts of traffic. As traffic bursts, we approach the natural threshold of a system. A system can only go as fast as the slowest part, (http://en.wikipedia.org/wiki/Amdahl%27s_law) so we need to make sure the slowest part is good enough for what business problem we are trying to solve.So should we cache everything at 5 seconds?
A 5 second cache isn't the answer to every problem though. Some content can't be cached at all. Like a shopping cart. Some content can be cached forever, like static content (named with a version number). Some content types do not seem cachable, but maybe could possibly be. An example would be a page listing inventory. Perhaps the business is able to fulfill limited quantities of out of stock items. Maybe the products don't change often and come in all the time. In this case, it might be ok to cache inventory for 5 seconds and handle out-of-stock items by delaying shipment. The right answer depends on the business problem and the constraints on solutions. Which is a better problem to have, a down website, or a few out-of-stock orders to deal with?Just for fun, let's look at the difference in caching for 5 seconds and caching for 5 minutes over 1 traffic hour:
- 720-20=700 @ 1 RPS
- 720-20=700 @ 5 RPS
- 720-20=700 @ 15 RPS
- 720-20=700 @ 30 RPS
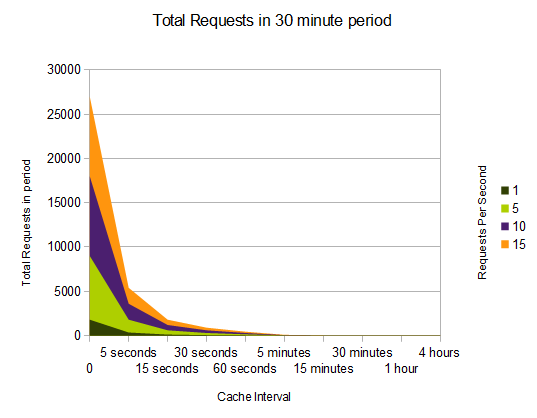
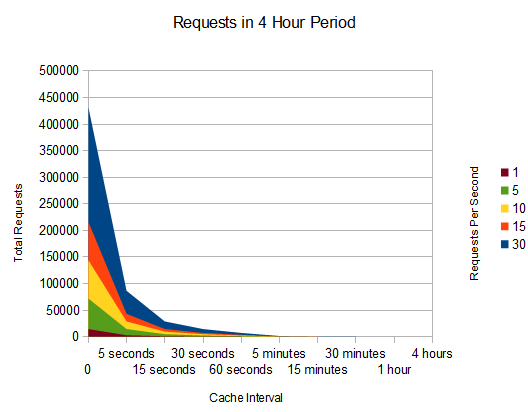
The second chart shows the total number of requests in a 4 minute period at different traffic level times. Note again, the 5 minute period as the point in which there is no visible benefit, considering the starting point.
The answer is, as always, "It Depends"
The right time to cache a piece of content really depends on all the elements in the equation. Caching, even in non-intuitive ways, can be used to solve business problems within the available solution constraints.
Build Better Forms Even Faster
Posted By : Dan Wilson
February 25, 2010 9:32 AM
I've been a big fan of the CFUniform ColdFusion Form Library for a long time. Using it helps me build better applications quicker. Matt Quackenbush has just released a major update to the library with some really compelling features.
Firstly, CFUniform is much more Ajax capable and plays even nicer in your Ajax application.
Secondly, there are several new types, like CAPTCHA and Rating.
Thirdly, there is much improved support for global configuration.
All of this leads to a more flexible and powerful form library to power your forms.
Take a look at the CFUniform 4.0 Release Article and find out more details.
Performance tuning for ColdFusion applications and Comment
Posted By : Dan Wilson
June 9, 2009 5:17 PM
Kunal Saini, an Adobe employee, recently posted an article on Adobe Developer Connection about Performance tuning for ColdFusion applications. This is a well written article full of useful tips and practices and should be a must read on the topic.
I will raise a counter point to one of the minor tips Kunal raised. He says:
compare() and compareNoCase()
Use compare() or compareNoCase() instead of the is not operator to compare two items. They are a bit faster.
I trust Kunal has insider knowledge about the implementations of these two compare functions, because I fail to see how a straight evaluation (<cfif dan IS 1337>) can be slower than a function call ( compare(dan, 1337) IS 0 ). Maybe it has to do with the type inference and type conversion ColdFusion does as a dynamically typed language, maybe it is something else. Regardless I avoid using compare() and compareNoCase() because both functions reduce the readability of the code.
Whereas all boolean comparisons in ColdFusion treat 1 as true and 0 as false, the compare and compareNoCase functions return 0 if the comparison is true. This means compare( 1, 1) will return 0, which doesn't follow the boolean rules. Since this does not follow the rules, code using compare and compareNoCase is harder to read, harder to follow, and generally uglier than straight comparisons.
So Kunal, I don't take anything away from your statements and I appreciate you writing the article. I want to point out that software isn't all about micro-performance, it is also about long-term maintainability. Always write your code to be readable by others.
Of course, if you happen to write the next Facebook and you need to squeeze every possible fraction of a millisecond out of a routine, then throw this advice right out the window. But then again, you'd have already tuned every single query permutation, added a clustered caching layer, offloaded your static files to a Content Delivery Network and clustered your infrastructure Horizontally and Vertically, haven't you?
The Art Of Method Names
Posted By : Dan Wilson
May 21, 2009 1:12 AM
I write from time to time on code quality and structure because it is a topic of interest to me. Clean code and well named logical structures, methods and objects really pay off during the infinitely long Support And Maintenance phase of software development.
Some could accuse me of having too many opinions on the topic, and I'd guess they could be on to something. Heck, I'll probably disagree with something I've said today, tomorrow, just because I'm always refining and learning.
While some of what I think/advocate/do is opinions, and could be subjective, I'd like to share some code I found on a project today and talk about the importance of method names.
A method should describe it's intent or behavior at the level of where it is inside the program. For example, a method named load() might be sufficiently descriptive to represent the behavior and be flexible enough to withstand a refactor or two. In other places in the program, perhaps the right method name is loadShippedOrders() since there will always be the concept of a shipped order in our proverbial system.
You get the point, right? There is a wide range of OK-ness for method names, with behavioral descriptiveness and refactorability as being two made up words that really judge the method name quality.
I found code today that really flies in the face of any of these principles. The names of these methods do not in any way describe any behavior of any system I've ever written, nor will probably be lucky enough to write.
method bodies removed to protect client interests
Be the Judge Yourself:
2 <cffunction name="phoneHome" output="yes">
3 </cffunction>
4
5 <cffunction name="createDir">
6 </cffunction>
7
8 <cffunction name="createDirImpl">
9 </cffunction>
10
11 <cffunction name="beamMeUp">
12 </cffunction>
13
14 <cffunction name="energize">
15 </cffunction>
16
17 <cffunction name="setPhaserToKill">
18 </cffunction>
19</cfcomponent>
Before you ask, this code was found in a production eCommerce system that is currently running that has nothing to do with Phasers, Energization nor beaming anything to any location.
Hard Coding Scopes In CFCs Is A No No!
Posted By : Dan Wilson
May 3, 2009 11:56 PM
Now Hear This!
This is a public service announcement. If you hard code scopes inside your CFCs (request, application, session), stop today.
I know it might be 'easier' or 'cleaner' or less lines of code, but you are really painting yourself into a corner when you do this.
An object (CFC) should not know or have access to ANYTHING outside of itself, its configuration and its immediate dependent objects.
If you want to question/argue with me on this, go for it. (Just go Read Up On Information Hiding before you do).
That Is All
If You Build or Maintain Client Side Libraries or Widgets I Want To Talk To You
Posted By : Dan Wilson
May 3, 2009 5:13 PM
The ColdFusion community is full of bright people who have built really neat libraries and widgets to make better features and functions for applications. One of my favorites, CFUniform (a rich forms library) lets you build consistent, feature rich forms with very minimal code. I use this library all the time to make my applications snazzier and more maintainable. There are plenty of cool projects I've not yet used and while working on some Model-Glue features this weekend, I had an idea.
See, I've been working on the scaffolding feature in Model-Glue. This feature is a great way to get a jump start on a data-centric application. Simply configure Model-Glue and your ORM of choice and Model-Glue will generate everything needed to Administrate your data. Forms, Lists, delete screens, Bam, it'll generate the whole thing for you in seconds. Of course, the generated code is easily customized to fit the need of the application, but because it is generated from the database, the functionality is generic and the look and feel is somewhat limited.
What if we had a real easy way to plug in some of these rich libraries into Model-Glue? Forms libraries, Ajax widgets, Grids, Rich tables, all these could be as simple as adding a few characters into an XML file. Sounds fun, right?
What I want is to talk to a few of the folks behind some of the coolest libraries to explore how I can provide the best integrations. If you are the author or maintainer of some library or widget, or you use something that you are really fond of, let me know by leaving a comment. We might be able to work together to provide some really neat, useful functionality for the community.
I Present Making Bad Code Good To The CFMeetup March 5th @ 6:00 EST
Posted By : Dan Wilson
March 2, 2009 6:11 PM
At 6:00 EST this Thursday, March 5th, I present Making Bad Code, Good to the Online ColdFusion Meetup. You can attend this presentation virtually, by visiting the Online ColdFusion Meeting Room at 6:00 EST.
If you work on a legacy application, or on code built by lots of developers over the years, you likely laugh your way through this presentation. I promise to be thought provoking and challenge the way you write code. In this session, we'll look at lots of code samples and walk through making incremental changes to speed development, reduce errors and make life easier for everyone involved.
Ideas and concepts in this presentation will help you improve your existing applications and write more maintainable code.
The recorded presentation can be watched now!
 Suscribe
Suscribe Follow Us
Follow Us Contact
Contact